
Intro
In the ever-evolving world of data engineering, new tools and technologies emerge regularly, each promising to simplify the complexities of managing and transforming data.
One such tool that has been gaining significant attention is the Data Build Tool, or DBT. While DBT officially reached version 1.0.0 in December 2021, its roots go back several years earlier when it was born out of a consulting project by Fishtown Analytics (now dbt Labs).
Today, DBT is an open-source project with a vibrant and growing community, addressing many challenges that data engineers and data-driven organizations have faced for years. After diving into what DBT has to offer, I was amazed by the breadth of problems it tackles—issues that data engineers grapple with daily. But is DBT truly the miracle tool that solves all your data problems? Let’s take a closer look.
Getting started with DBT
One of the most appealing aspects of DBT is how accessible it is, even for those who are not seasoned data engineers. At its core, DBT is SQL-centric, which makes it immediately familiar to data analysts and engineers alike.
# for poetry users
poetry new my_dbt_project
cd my_dbt_project
poetry add dbt-core
poetry add dbt-databricks
poetry shell
dbt init my_dbt_projectTo get started, you don’t need to learn a new programming language or master a complex interface. If you know SQL, you can start using DBT almost immediately. The installation process is straightforward, with options to run DBT locally or through its cloud offering, DBT Cloud, which further simplifies deployment and management.
To integrate DBT with for example Databricks, we need addition module: dbt-databricks and we will need to configure profiles.yml file with the appropriate settings for our Databricks environment. The profiles.yml file is typically located in ~/.dbt/.
my_project:
outputs:
dev:
type: databricks
catalog: hive_metastore
schema: analytics
host: <your-databricks-host>
http_path: <your-databricks-http-path>
token: <your-databricks-token>
target: dev
Once set up, DBT allows you to organize your SQL queries into models, which are then used to build transformations in your data warehouse.
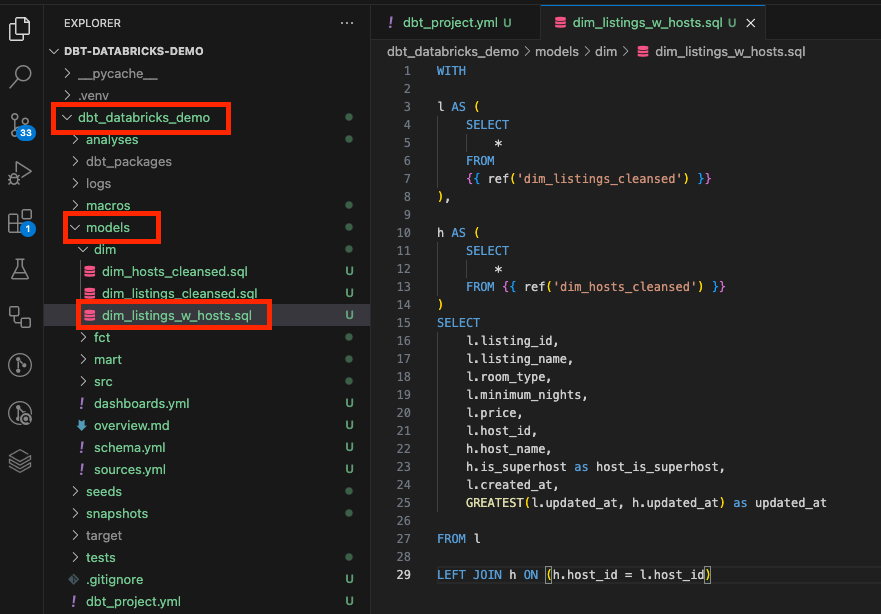
After adding your first model, you can simply run:
dbt runThis modular approach not only makes your SQL code more reusable and maintainable but also provides a clear structure that scales as your data needs grow.
What is all the hype about?
As we have seen, it’s really easy to get started with DBT. And it has garnered substantial hype for a good reason. It solves several pain points that have long plagued data engineers and analysts. Here’s why it’s generating so much buzz:
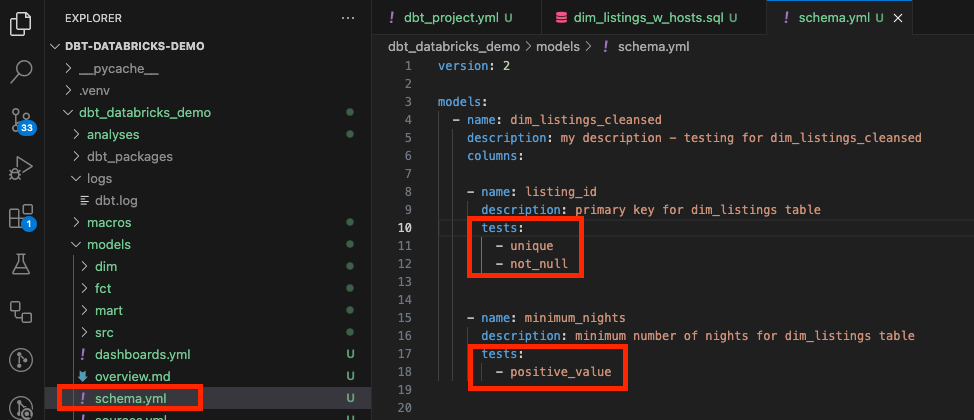
Automated Data Quality
DBT takes data quality seriously. It allows you to write tests directly within your data transformation workflows, ensuring that your data remains consistent and accurate. These tests can check for things like null values, unique constraints, or even custom business logic, all while being tightly integrated into the transformation process. One can also run custom-made SQL-like tests.
Seamless Integration
DBT integrates seamlessly with modern data warehouses like: Amazon Redshift, Apache Spark, Azure Synapse, Databricks, Google BigQuery Microsoft Fabric, PostgreSQL, Snowflake, as well as version control systems like Git (full list here).
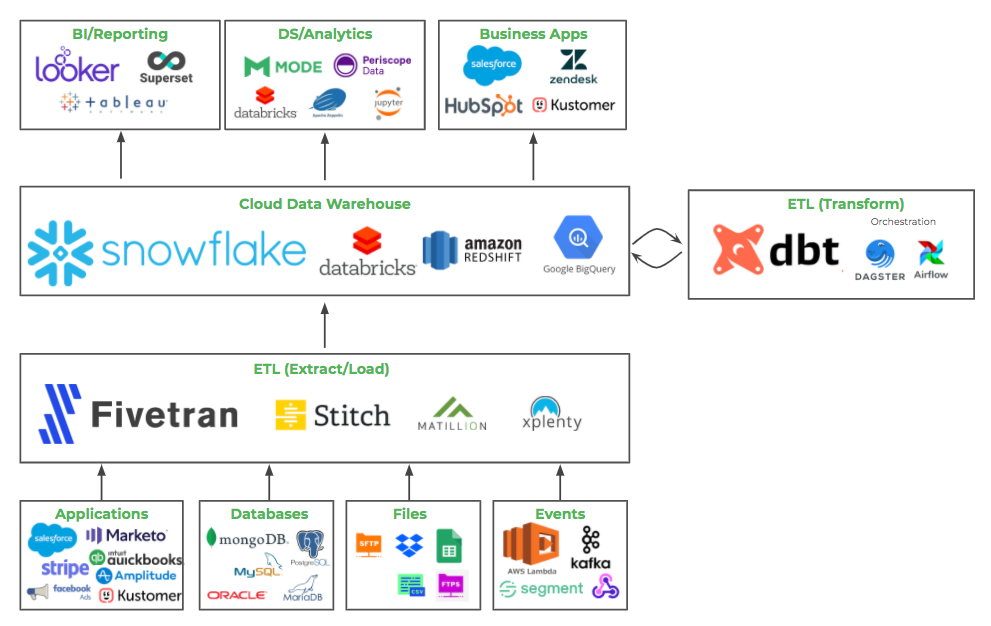
This means that your data transformations can be versioned, reviewed, and deployed just like any other piece of software, bringing best practices from software engineering into the data world.
Docs as Code
Documentation is often a neglected aspect of data engineering, but DBT changes that with its “docs as code” approach. Since documentation is generated alongside your transformations, it stays up-to-date with minimal effort. You just need to run:
dbt docs generate
dbt docs serve
>>> Serving docs at 8080
>>> To access from your browser, navigate to: http://localhost:8080
>>> Press Ctrl+C to exit.
>>> 127.0.0.1 - - [24/Aug/2024 14:37:50] "GET / HTTP/1.1" 200 -
>>> 127.0.0.1 - - [24/Aug/2024 14:37:50] "GET /manifest.json?cb=1724503070952 HTTP/1.1" 200 -
>>> 127.0.0.1 - - [24/Aug/2024 14:37:50] "GET /catalog.json?cb=1724503070952 HTTP/1.1" 200 -Example:
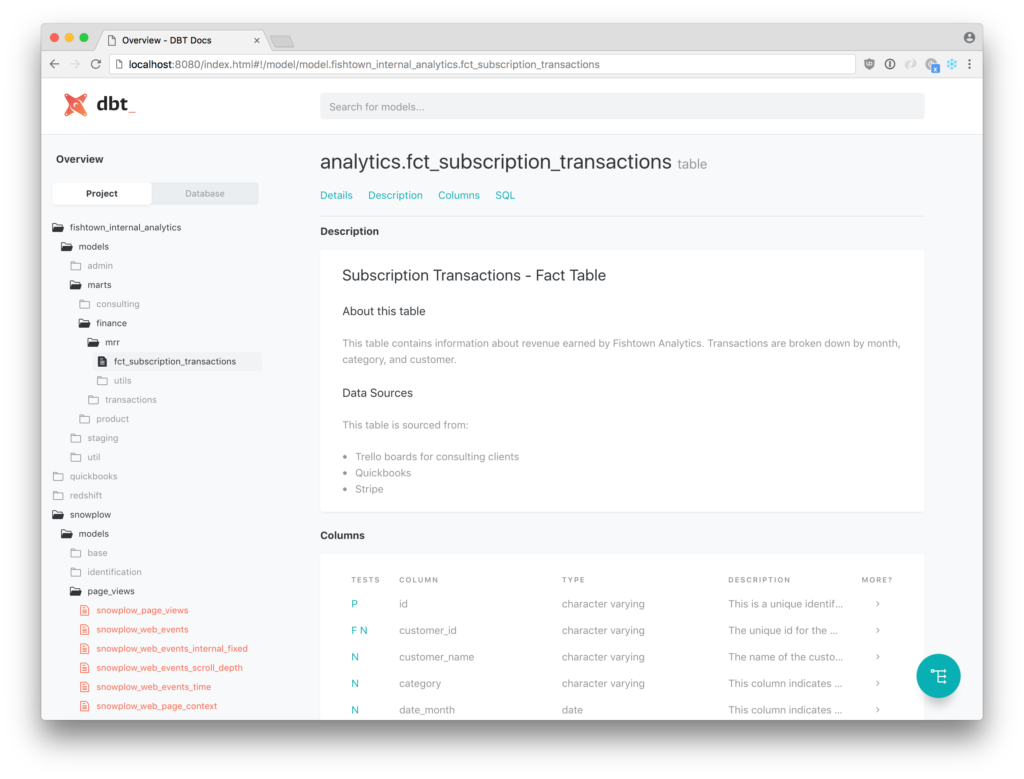
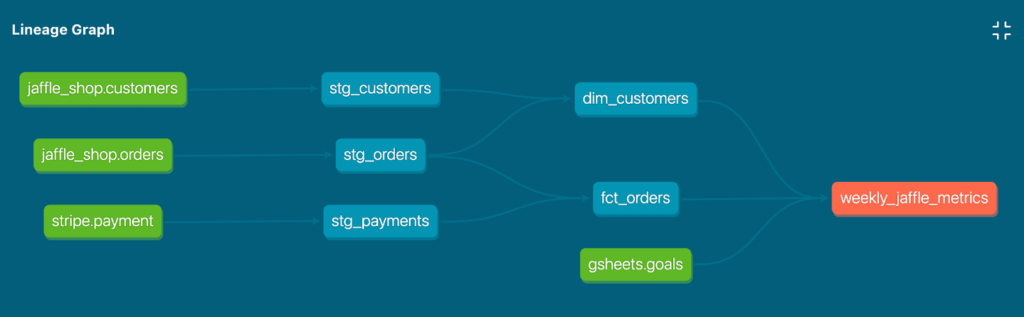
DBT even auto-generates lineage graphs, which visualize the relationships and dependencies between your data models. If you’ve ever spent hours manually updating a lineage graph after introducing new features, you’ll appreciate the time-saving power of DBT.
Example:
Support for Slowly Changing Dimensions (SCDs)
Handling slowly changing dimensions is a common challenge in data warehousing. DBT provides built-in support for SCDs, allowing you to manage historical changes in your data with ease. Example:
{{
config(
materialized = 'incremental',
on_schema_change='fail'
)
}}
WITH src_reviews AS (SELECT * FROM {{ ref('src_reviews') }})
SELECT
{{ dbt_utils.generate_surrogate_key(['listing_id', 'review_date', 'reviewer_name', 'review_text']) }}
AS review_id,
*
FROM src_reviews
WHERE review_text is not null
{% if is_incremental() %} AND review_date > (select max(review_date) from {{ this }})
{% endif %}This is especially useful for organizations that need to maintain accurate historical records without overwriting past data.
SQL-Centric
Because DBT relies heavily on SQL, it’s easy to pick up and start using. This lowers the barrier to entry and allows teams to leverage their existing SQL knowledge. DBT’s use of the Jinja templating engine also means you can create dynamic and reusable SQL code, further enhancing productivity.
All problems solved, we can now go home
Not so fast…
While dbt offers numerous benefits and is straightforward to set up locally with the dbt run command, deploying it in a production environment requires more than just a simple hello world setup. To ensure a robust, production-grade service, you need to manage three environments—dev, test, and prod—and ensure high availability. What’s more, DBT is often best paired with an orchestration service, i.e. Dagster, Azure Data Factory or Apache Airflow to name a few.
So, where should you host your dbt service? How can you avoid waking up at 3 a.m. to run dbt run from your laptop?

There are several hosting options worth exploring, including:
- Kubernetes clusters (e.g., Azure AKS, AWS EKS)
- App/docker managed services (e.g., Azure App Service, AWS Elastic Beanstalk)
I might explore these options in future articles.
For a simpler approach, consider integrating dbt commands into your CI/CD pipeline, using tools like GitHub Actions or Azure DevOps:
- Development branch = development environment
- Master branch = test environment
- Code release = production environment
Conclusion
DBT is a powerful tool for modern data stacks, addressing challenges like data quality, documentation, complex transformations, and historical accuracy. Its SQL-centric design, strong community, and seamless integrations make it a valuable asset for data teams.
However, DBT isn’t a cure-all. It specializes in transforming data within a warehouse but doesn’t handle data extraction, loading, or other ETL tasks. For a complete ETL solution, it should be used with other complementary tools.
In short, DBT revolutionizes data transformation and simplifies managing data workflows, though it doesn’t resolve every data issue.
Happy coding!
Filip