
Have you ever worked on a data engineering project where there was no clear way to isolate your development work from other engineers? It might look something like this:
Business as usual in our main development data environment…

Then Jake starts developing a new feature. He modifies tables: Silver_1 and Gold_1.
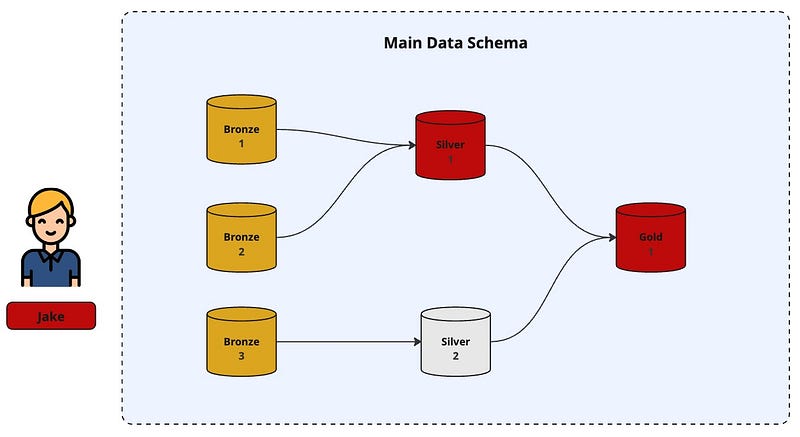
Simultaneously, Paul begins working on another feature and modifies Silver_2 and Gold_1.

Later, Jake spends two frustrating hours debugging his changes, only to realize that his logic was perfectly fine — Paul had overwritten Gold_1 in the background.
Jake starts to wonder whether he should have taken over his father’s dry-cleaning business after all. Maybe this life of silent table conflicts wasn’t meant for him.
Sounds familar, minus the dry-cleaning?
There has to be a better way
Enters isolated data schemas.

The goal is simple: developers should be able to work independently without stepping on each other’s toes. Once they’re done, they can safely merge their changes into the main environment.

In the visual above, both Jake and Paul work in isolated environments. They make changes, test confidently, and merge clean code into main branch. Jake’s father is proud.
How to achieve schema isolation in Databricks?
Here are three practical ways to isolate development environments in Databricks.
- Use Databricks Asset Bundles (Recommended)
Databricks engineers saw this coming — and built a solution into Databricks Asset Bundles. All you need is a development mode in your databricks.yml.# databricks.yml
# databricks.yml
targets:
dev_user:
# The default target uses 'mode: development' to create a development copy.
# - Deployed resources get prefixed with '[dev my_user_name]'
# - Any job schedules and triggers are paused by default.
# See also https://docs.databricks.com/dev-tools/bundles/deployment-modes.html.
mode: development # <<<- magic line!
default: true
workspace:
host: https://adb-1592122XXXXXXXXX.15.azuredatabricks.netThen deploy your development bundle:databricks bundle deploy -t dev_user
databricks bundle deploy -t dev_user
>>> Uploading bundle files to /Workspace/Users/filipxxxxxxxxxxxx@gmail.com/.bundle/cncdemo/dev_user/files...
>>> Deploying resources...
>>> Updating deployment state...
>>> Deployment complete!And my demo workflow:
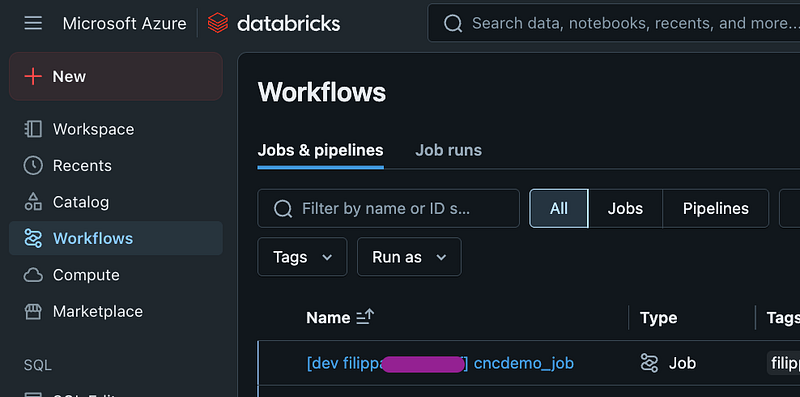
test_table created as a part of this workflow is now part of my own personal schema, not interfering with anyone else’s work.

2. Use DBT with Dynamic Schema Prefixing
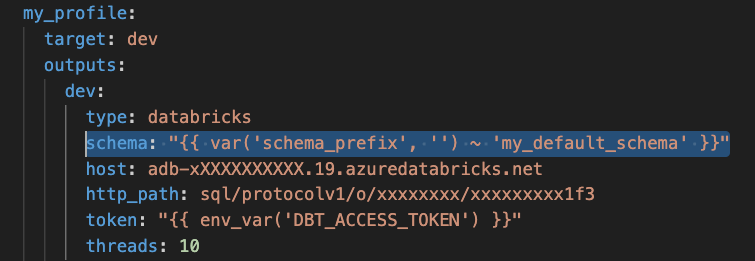
If you’re using DBT, isolating schemas is easy with this simple tweak in profiles.yml:
schema: "{{ var('schema_prefix', '') ~ 'my_default_schema' }}"
Now run:
dbt run -t $DBT_ENV — vars ‘{schame_prefix: filip_}’,
Your tables will be created under: filip_my_default_schema
If you omit the variable and run:
dbt run -t $DBT_ENV,
schema would default to: my_default_schema. Simple as that.
3. Use environment variables or user context
For teams running custom jobs or notebooks, you can isolate data based on who runs the code using the built-in context API.
# for notebook users:
dbutils.notebook.entry_point.getDbutils().notebook().getContext().userName().get()
>>> 'filipxxxxxxxxxxxxx@gmail.com'
# for all other users:
spark.sql('select current_user() as user').collect()[0]['user']
>>> 'filipxxxxxxxxxxxxx@gmail.com'Now you can dynamically prefix your schemas or tables based on the active user – giving each engineer a private workspace.
✨ Bonus: impact assessment option unlocked!
With isolated schemas, you unlock an added benefit:
You can validate your data changes independently before merging to production. That means fewer bugs, safer deployments, and more confidence in your work.

Summary
We explored three ways to create isolated development environments in Databricks:
- Databricks Asset Bundles — Native and powerful (recommended)
- DBT schema prefixing — Lightweight and CI/CD-friendly
- User-based schema logic — Great for notebooks or custom apps
Personally, I recommend using Databricks Asset Bundles if you’re already invested in the Databricks ecosystem. But for more flexibility or integration with tools like DBT, options 2 and 3 work just as well.
Happy coding, and may your tables never clash again.
— Filip