
Introduction
Welcome to the wild world of data, where lakes aren’t just for swimming, and warehouses aren’t just for storing physical goods. In this article, we’ll dive into the quirks and differences between data lakes, delta lakes, data warehouses, data lakehouses, and the latest kid on the block – data mesh.
Data Lake: The Inclusive Data Storage

A Data Lake is a centralised repository that allows organisations to store data of all types – structured, semi-structured, and unstructured – at any scale without the constraints of a predefined schema. It’s the starting point for data exploration, where information swims freely, often causing confusion among analysts trying to fish out relevant insights. It’s like searching for a specific fish in the ocean – good luck!
Delta Lake: Where Change is the Only Constant

Enter delta lake, the cool cousin of the data lake. An extension of Apache Spark that introduces ACID (Atomicity, Consistency, Isolation, Durability) transactions and version control into your data, which ensures that your data changes are as smooth as a swan gliding on water. Also, as a bonus, it enables data time travel to previous checkpoint.
Data Warehouse: Hot but High Maintenance

Contrastingly, a data warehouse is more like an architectural marvel. It’s designed for structured data, meticulously organized and optimized for efficient querying. It is primarily designed for heavy reads and reporting, offering high performance for complex queries. It uses schema-on-write approach, meaning data is structured before it is stored, ensuring consistency in the stored information. It’s like Marie Kondo came to town and gave your data a makeover. Nice and tidy, but you have to put in the effort and keep it clean.
Data Lakehouse: A Data Love Story

Data Lakehouse combines the strengths of both Data Lakes and Data Warehouses. It merges the flexibility and scalability of Data Lakes with the structured processing and query performance of Data Warehouses. This hybrid approach aims to overcome the limitations of traditional Data Warehouses and enhance the capabilities of Data Lakes. It’s a bit like an odd couple sitcom, where raw, unstructured data learns to live harmoniously with the well-organized, structured data.
Is it too good to be true? Perhaps, but the magic lies in the intricate elements that make it work:
- Catalog Services – Data Lakehouse architectures often include catalog services that act as a centralized repository for metadata. These services store metadata in a structured format, making it easy to query and manage.
- Metadata Store – Some Data Lakehouse implementations utilize dedicated metadata stores or databases to store metadata.
- Unified Catalog – A unified catalog approach involves consolidating metadata from different sources into a central catalog. This catalog provides a comprehensive view of the metadata landscape within the Data Lakehouse.
- Schema Registry – For scenarios where schema evolution is a key concern, a schema registry may be employed to manage metadata related to schema changes. This ensures that changes are tracked, documented, and applied consistently.
- Metadata APIs – Metadata can be accessed and managed through dedicated APIs. These APIs enable programmatic interactions with the metadata layer, allowing automation of certain metadata-related tasks.
Though delta lake itself is not equvalent to a data lakehouse architecture, it enables the implementation of the DLH by adding features like transaction management and audit capabilities.
Data Mesh: The Avengers of Data Architecture
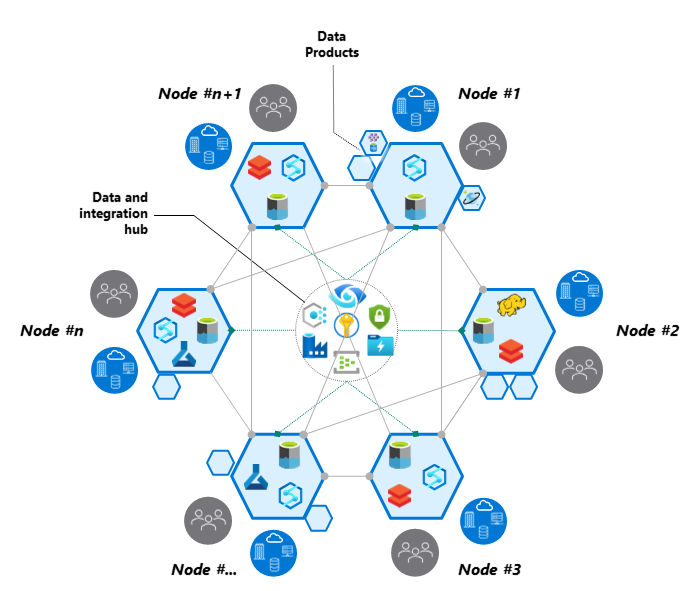
Is the new kid on the block just another paradigm shift, a game-changer, or just too much hype? You can’t always have it all, even though the Data Lakehouse seemed to come close. Sometimes we need to halt the central planning and think local. Enter data mesh.
In the realm of data superheroes, data mesh is the Avengers. Decentralized, scalable, and collaborative – it’s the dream team of data architecture. Let’s explore some crucial concepts:
- Domain-Oriented Data Ownership – It champions a domain-oriented approach, where each data domain is owned and managed by a specific domain team.
- Federated Data Architecture – In contrast to a centralized approach, it allows for greater scalability and autonomy, distributing data responsibilities across different business units or domains.
- Data as a Product – Encouraging a more thoughtful and customer-centric mindset, treating data as a valuable product with well-defined APIs and service-level agreements.
Now, when would you use it?
- Scalability Challenges – When grappling with scalability issues in a centralized data approach, and there’s a need to distribute data responsibilities across different business units or domains.
- Autonomous Product Teams – When organizations aim to empower autonomous product teams to own and manage their data products, fostering innovation and agility.
- Complex Business Domains – In scenarios where the business has complex and diverse domains with varied data needs, and a one-size-fits-all approach is not effective.
Data mesh brings the promise of a more flexible, collaborative, and domain-focused approach to data architecture, offering a solution to some of the challenges posed by traditional centralized models.
Conclusion
Thank you for visiting this data circus! In the end, whether you’re swimming in lakes, dancing with deltas, tidying up warehouses, harmonizing in lakehouses, or meshing with the Avengers, remember—it’s all part of the grand data symphony.
Happy coding, cheers!
Filip