
Intro
One of the key factors that accelerates a team’s productivity is an efficient development workflow. A streamlined workflow typically looks like this:
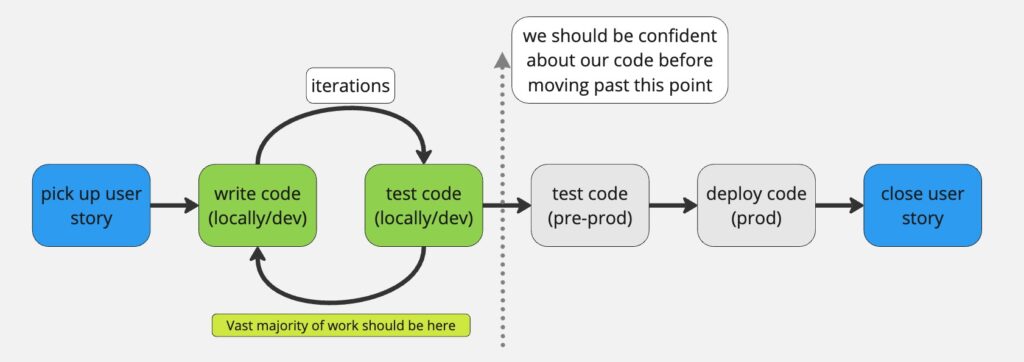
As we can see, the faster we can write and test code in the local or development environment, the shorter the feedback loop becomes. This directly improves development speed.
shorter code write-test cycles => higher team productivity
When and why to use production data in development?
From a development speed perspective, we would ideally have access to production data in dev.
This is okay if:
- Data is anonymized: to protect privacy.
- Security matches production: with encryption, iam controls and safeguards.
- Compliance is ensured: with legal and regulatory standards.
However, at times we are unable to do that for various reasons:
- Privacy concerns: with sensitive data (public safety, banking, government, etc.)
- Regulatory restrictions: like GDPR or HIPAA.
- Risk of data leakage: in less secure environments.
- Environment differences: leading to inaccurate results.
If we simply can’t use prod data in dev, we need to get creative…
What if using prod data in dev is simply NOT an option?
In such case we have 2 options:
- Masking data
This involves anonymizing sensitive information, such as personal identifiers, while preserving the structure and relationships within the data. Masked data allows developers to test with realistic datasets without compromising privacy or security, making it useful for scenarios where real-world behavior needs to be simulated. - Creating synthetic/dummy data from scratch
Synthetic data is completely generated to mimic production data patterns without using any actual user data, though it may not capture all edge cases of real-world data.
For obvious reasons creating syntetic data is the most secure, but it comes with certain limitations:
- all relationships in the data are very hard to replicate (i.e. status change for slowly changing dimenstions or properties for specific client groups in some conditions)
- hard to get any meaningful processing outcomes
- not possible to get realistic code performance since synthetic data is usually significantly smaller than real data
In the example below, I would like to present how to safely mask our sensitive data.
Talk is cheap, show me the code
All the code can be found in this repo.
Step 1 — create sample data
from pyspark.sql import SparkSession
spark = (
SparkSession
.builder.master("local")
.appName("create_fake_data")
.getOrCreate()
)
SAMPLE_DATA = [
(100, "2024-05-03 19:17:53", "Jack", "Paul", "jack.paul@gmail.com", "US", "a-1", 83.50, "hoodie"),
(100, "2024-04-20 10:20:01", "Jack", "Paul", "jack.paul@gmail.com", "US", "a-2", 72.30, "trousers"),
(200, "2023-12-03 11:10:42", "Maria", "Sharak", "m.rak@hotmail.com", "ES", "b-2", 120.10, "jacket"),
(300, "2023-09-07 18:02:29", "Maciej", "Wilk", "djmac@onet.pl", "PL", "c-3", 25.90, "beanie"),
]
SAMPLE_SCHEMA = """
client_id integer,
event_date string,
first_name string,
last_name string,
email string,
country_cd string,
transaction_id string,
transaction_amount_usd double,
product_cd string
"""
data = spark.createDataFrame(
data = SAMPLE_DATA,
schema = SAMPLE_SCHEMA,
)
data.show()
data.write.format("parquet").mode("overwrite").save("./data/sample-prod-data/")Step 2 — load the data
from pyspark.sql import SparkSession
from faker import Faker
spark = (
SparkSession
.builder.master("local")
.appName("anonymise_data")
.getOrCreate()
)
df = spark.read.format("parquet").load("./data/sample-prod-data/")
df.show()+---------+-------------------+----------+---------+-------------------+----------+------------------------------------+----------------------+----------+
|client_id|event_date |first_name|last_name|email |country_cd|transaction_id |transaction_amount_usd|product_cd|
+---------+-------------------+----------+---------+-------------------+----------+------------------------------------+----------------------+----------+
|100 |2024-05-03 19:17:53|Jack |Paul |jack.paul@gmail.com|US |5c93a148-13ac-4edf-847c-b02b24314d3b|83.5 |hoodie |
|100 |2024-04-20 10:20:01|Jack |Paul |jack.paul@gmail.com|US |91db632b-cfa9-47c1-95a1-51e1681eb8af|72.3 |trousers |
|200 |2023-12-03 11:10:42|Maria |Sharak |m.rak@hotmail.com |ES |83d8bd8d-89ff-4882-820c-1a3808c85b20|120.1 |jacket |
|300 |2023-09-07 18:02:29|Maciej |Wilk |djmac@onet.pl |PL |419fde3d-c243-4b22-98a1-81d40cffc0ac|25.9 |beanie |
+---------+-------------------+----------+---------+-------------------+----------+------------------------------------+----------------------+----------+Step 3— (optional) — sample data
In case of large datasets — in our examples I would select all records (fraction=1.0):
DATA_SAMPLE = 1.0 # 0.1
df_sampled = df.sample(withReplacement=False, fraction=DATA_SAMPLE)Step 4 — load Faker — example:
fake = Faker()
print(f"Fake name: {fake.name()}")
print(f"Fake adress: {fake.address()}")
print(f"Fake email: {fake.ascii_email()}")
print(f"Fake bank account: {fake.bban()}")
print(f"Fake date of birth: {fake.date_of_birth()}")
print(f"Fake phone number: {fake.basic_phone_number()}")>>> Fake name: Tyler Murphy
>>> Fake adress: 02821 Smith Street, West Charlesview, KS 57206
>>> Fake email: dorothybrown@hotmail.com
>>> Fake bank account: FHSG55887263983130
>>> Fake date of birth: 1999-08-24
>>> Fake phone number: (787)929-2124Step 5 — mask the data at scale
df_masked = df_sampled
anyonymization_configs = [
{
"col_name": "client_id",
"faker_fun": fake.unique.random_int,
"args": {"min": 100, "max": 500},
},
{
"col_name": "first_name",
"faker_fun": fake.unique.first_name,
"args": {},
},
{
"col_name": "last_name",
"faker_fun": fake.unique.last_name,
"args": {},
},
{
"col_name": "email",
"faker_fun": fake.unique.email,
"args": {},
},
{
"col_name": "country_cd",
"faker_fun": fake.unique.country_code,
"args": {},
},
{
"col_name": "transaction_id",
"faker_fun": fake.unique.uuid4,
"args": {},
},
{
"col_name": "transaction_amount_usd",
"faker_fun": fake.unique.random_int,
"args": {"min": 100, "max": 500},
},
]
for anyonymization_config in anyonymization_configs:
col_name = anyonymization_config["col_name"]
faker_fun = anyonymization_config["faker_fun"]
args = anyonymization_config["args"]
distinct_col_values = [value[0] for value in df_masked.select(col_name).drop_duplicates().collect()]
replace_vals = {dcv: faker_fun(**args) for dcv in distinct_col_values}
df_masked = df_masked.replace(replace_vals, subset=col_name)
df_masked.show(truncate=False)+---------+-------------------+----------+---------+-------------------------+----------+------------------------------------+----------------------+----------+
|client_id|event_date |first_name|last_name|email |country_cd|transaction_id |transaction_amount_usd|product_cd|
+---------+-------------------+----------+---------+-------------------------+----------+------------------------------------+----------------------+----------+
|303 |2024-05-03 19:17:53|Alicia |Baker |xmahoney@example.net |PS |444ed2b1-91f2-4172-b5ee-b4b31619037f|175.0 |hoodie |
|303 |2024-04-20 10:20:01|Alicia |Baker |xmahoney@example.net |PS |3db4b9af-596b-4140-a689-22f731768b54|387.0 |trousers |
|429 |2023-12-03 11:10:42|Natalie |Bailey |stevensimmons@example.com|CH |b1ddf8eb-74ee-41f5-819e-63e98faf1243|156.0 |jacket |
|403 |2023-09-07 18:02:29|John |Day |molinanicole@example.com |KE |93cb6cf6-816b-4138-bbc0-86356c214f0a|406.0 |beanie |
+---------+-------------------+----------+---------+-------------------------+----------+------------------------------------+----------------------+----------+Please look that in our example, relationships between the data are perserved:
client_id,first_name,last_name,emailandcountry_cdis the same for first 2 rowsevent_dateandproduct_cdwere not replaced since they are considered not sensitive
Summary
We’ve discussed how masking addresses data sensitivity challenges. However, several additional factors need attention:
1. Automating the process to adapt to changes in upstream data.
2. Choosing the right hosting solution.
3. Ensuring performance as data volume grows exponentially.
Despite these considerations, this framework serves as a strong starting point for further development.
Happy coding!
Filip