
Introduction
Picture this: at the heart of Delta Lake, there’s a bustling hub of activity known as the Delta Log. It’s like the control tower of your data universe, meticulously documenting every twist and turn in the journey of your Delta tables. Think of it as the guardian angel ensuring the reliability and consistency of your data, making sure every operation is as smooth as silk.
Now, the Delta Log isn’t just some mundane ledger tucked away in a digital corner. It’s a collection of JSON files, containg the metadata that tells the story of your data over time. Inside these files, you’ll find the details about transactions, updates, additions, and deletions.
But how does the Delta Log look, and what information does it contain? Buckle up, because we’re diving right it.
Setup
Env setup
from config import Environments
from config import Buckets
from tests.setup import drop_all_tables
from pyspark.sql import SparkSession
environment = Environments.LOCAL
bucket = Buckets[environment.value].value
table_name = "my_table"
table_path = f"{bucket}/{table_name}"
print(f"{environment=}")
print(f"{bucket=}")
print(f"{table_path=}") >>> environment=<Environments.LOCAL: 'LOCAL'>
>>> bucket='/tmp/deltalake'
>>> table_path='/tmp/deltalake/my_table'spark = (
SparkSession
.builder
.appName("DeltaLogApp")
.config("spark.jars.packages", "io.delta:delta-spark_2.12:3.1.0")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog",)
.getOrCreate()
)Creating sample data:
# Sample data #1
data = [("Alice", 25), ("Bob", 30), ("Jake", 59)]
# Define a schema
schema = """name:string, age:integer"""
# Create a DataFrame
df = spark.createDataFrame(data, schema=schema)
df.show()+-----+---+
| name|age|
+-----+---+
|Alice| 25|
| Bob| 30|
| Jake| 59|
+-----+---+Writing our first delta table:
So far the Delta directory: /tmp/deltalake is empty as we can see:
➜ deltalake pwd
/tmp/deltalake
➜ deltalake tree
.
0 directories, 0 files
Let’s write some data and repartition it so that we only have one output file:
# Write data to a Delta table
df.repartition(1).write.format("delta").mode("overwrite").save(table_path)After the write we observe:
parquetfile with written data_delta_logJSON file with Delta config.
➜ deltalake pwd
/tmp/deltalake
➜ deltalake tree
.
└── my_table
├── _delta_log
│ └── 00000000000000000000.json
└── part-00000-14e800a0-ed66-4f2a-b973-c33e140ebbdd-c000.snappy.parquet
3 directories, 2 filesLet’s inspect the JSON log file now.
Anatomy of a _delta_log
Now, let’s explore what occurred within the _delta_log. Four rows were written into the file. Here’s how they appear:
{"add":{"path":"part-00000-14e800a0-ed66-4f2a-b973-c33e140ebbdd-c000.snappy.parquet","partitionValues":{},"size":704,"modificationTime":1710185821141,"dataChange":true,"stats":"{\"numRecords\":3,\"minValues\":{\"name\":\"Alice\",\"age\":25},\"maxValues\":{\"name\":\"Jake\",\"age\":59},\"nullCount\":{\"name\":0,\"age\":0}}"}}
{"commitInfo":{"timestamp":1710185821282,"operation":"WRITE","operationParameters":{"mode":"Overwrite","partitionBy":"[]"},"isolationLevel":"Serializable","isBlindAppend":false,"operationMetrics":{"numFiles":"1","numOutputRows":"3","numOutputBytes":"704"},"engineInfo":"Apache-Spark/3.5.1 Delta-Lake/3.1.0","txnId":"7484fa8e-2a23-4119-b4c0-affdff5b5123"}}
{"metaData":{"id":"b61627c2-beaf-406b-ae65-bfc04d35b465","format":{"provider":"parquet","options":{}},"schemaString":"{\"type\":\"struct\",\"fields\":[{\"name\":\"name\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"age\",\"type\":\"integer\",\"nullable\":true,\"metadata\":{}}]}","partitionColumns":[],"configuration":{},"createdTime":1710185820898}}
{"protocol":{"minReaderVersion":1,"minWriterVersion":2}}Let’s break down the meaning of each row:
add:
- Purpose: Represents the addition of new data to the Delta table.
- Usage: When new files or data partitions are added to the Delta table, an
addoperation is recorded in the Delta Log. This allows for tracking the lineage and history of data additions.
{
"add": {
"path": "part-00000-14e800a0-ed66-4f2a-b973-c33e140ebbdd-c000.snappy.parquet",
"partitionValues": {},
"size": 704,
"modificationTime": 1710185821141,
"dataChange": true,
"stats": {
"numRecords": 3,
"minValues": {
"name": "Alice",
"age": 25
},
"maxValues": {
"name": "Jake",
"age": 59
},
"nullCount": {
"name": 0,
"age": 0
}
}
}
}
Any additional file corresponds to an additional ‘add’ row in the _delta_log file. Since we repartitioned the DataFrame and now have only one partition, we will observe only one ‘add’ JSON row.
commitInfo:
- Purpose: Captures metadata related to a committed transaction.
- Usage: Contains information about the commit, such as the user who committed the transaction, the timestamp, and any additional user-defined metadata. It provides a snapshot of the transaction details for auditing and tracking purposes.
{
"commitInfo": {
"timestamp": 1710185821282,
"operation": "WRITE",
"operationParameters": {
"mode": "Overwrite",
"partitionBy": "[]"
},
"isolationLevel": "Serializable",
"isBlindAppend": false,
"operationMetrics": {
"numFiles": "1",
"numOutputRows": "3",
"numOutputBytes": "704"
},
"engineInfo": "Apache-Spark/3.5.1 Delta-Lake/3.1.0",
"txnId": "7484fa8e-2a23-4119-b4c0-affdff5b5123"
}
}metadata:
- Purpose: Records changes to the Delta table’s metadata.
- Usage: When there are modifications to the Delta table’s schema, configuration, or other metadata properties, the
metadataoperation is used. This allows tracking changes to the structural aspects of the Delta table.
{
"metaData": {
"id": "b61627c2-beaf-406b-ae65-bfc04d35b465",
"format": {
"provider": "parquet",
"options": {}
},
"schemaString": {
"type": "struct",
"fields": [
{
"name": "name",
"type": "string",
"nullable": true,
"metadata": {}
},
{
"name": "age",
"type": "integer",
"nullable": true,
"metadata": {}
}
]
},
"partitionColumns": [],
"configuration": {},
"createdTime": 1710185820898
}
}protocol:
- Purpose: Records changes to the Delta protocol version.
- Usage: When there are updates or changes to the Delta protocol (internal Delta Lake protocol), the
protocoloperation is used. This is essential for maintaining compatibility and ensuring proper communication between different versions of Delta Lake.
{
"protocol": {
"minReaderVersion": 1,
"minWriterVersion": 2
}
}Creating new sample data
In the example below, the data is slightly adjusted:
# Sample data #1
#data = [("Alice", 25), ("Bob", 30), ("Jake", 59)] <-- OLD
data = [("Kate", 44), ("Bob", 30), ("Jake", 100)]
# Define a schema
schema = """name:string, age:integer"""
# Create a DataFrame
df = spark.createDataFrame(data, schema=schema)
df.show()+----+---+
|name|age|
+----+---+
|Kate| 44|
| Bob| 30|
|Jake|100|
+----+---+We then overwrite our original Delta table using the new data:
# Write data to a Delta table
df.repartition(1).write.format("delta").mode("overwrite").save(table_path)As a result, we observe changes in the folder structure following the second write operation:
➜ deltalake pwd
/tmp/deltalake
➜ deltalake tree
.
└── my_table
├── _delta_log
│ ├── 00000000000000000000.json
│ └── 00000000000000000001.json
├── part-00000-14e800a0-ed66-4f2a-b973-c33e140ebbdd-c000.snappy.parquet
└── part-00000-76982af1-0bd9-404b-8fb5-d5eb478987ea-c000.snappy.parquet
3 directories, 4 filesUpon inspecting the files, we notice that nothing has changed in the old files! Both the old Parquet file and the old _delta_log file have remained intact! This reveals that the _delta_log operates on an append basis, ensuring that one can always revert to the previous state.
Let’s examine how the new _delta_log file differs (files have been formatted for readability) – old file on the left, new on the right:
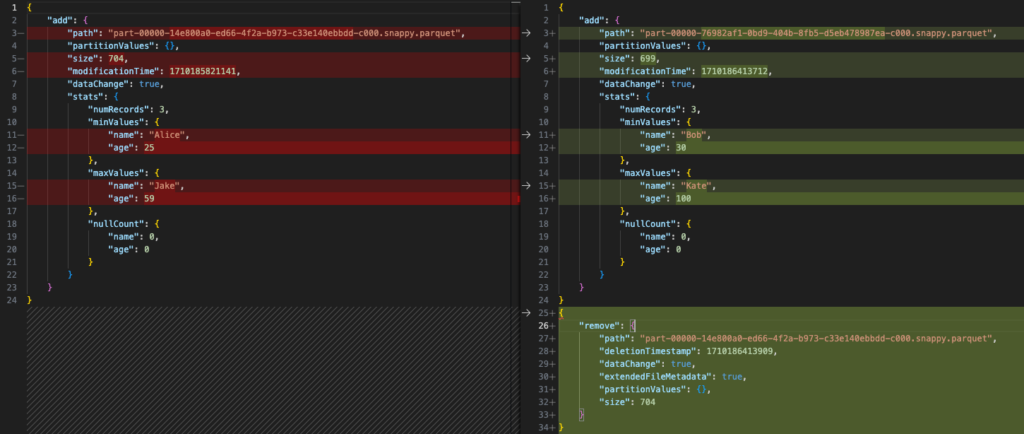


The most significant changes can be observed within the add and remove sections. Old files were removed, and new ones are now included in the most recent table version.
Creating 3rd sample data
Now, let’s experiment with the schema. Delta offers a table schema evolution feature, allowing for seamless adaptation to changes.
# Sample data #1
# data = [("Alice", 25), ("Bob", 30), ("Jake", 59)] <-- OLD v1
# data = [("Kate", 44), ("Bob", 30), ("Jake", 100)] <-- OLD v2
data = [("Kate", 44, "Smooth Alice"), ("Bob", 30, "Steezy Bob"), ("Jake", 100, "Speedy Jake")]
# Define a schema
schema = """name:string, age:integer, nickname:string"""
# Create a DataFrame
df = spark.createDataFrame(data, schema=schema)
df.show()+----+---+------------+
|name|age| nickname|
+----+---+------------+
|Kate| 44|Smooth Alice|
| Bob| 30| Steezy Bob|
|Jake|100| Speedy Jake|
+----+---+------------+In most Databricks runtimes, the autoMerge schema evolution feature is enabled by default. However, locally, to enable schema evolution, we need to execute:
spark.conf.set("spark.databricks.delta.schema.autoMerge.enabled", "true")Then we can run:
# Write data to a Delta table
df.repartition(1).write.format("delta").mode("overwrite").save(table_path)New delta_log and parquet files have appeared:
➜ deltalake pwd
/tmp/deltalake
➜ deltalake tree
.
└── my_table
├── _delta_log
│ ├── 00000000000000000000.json
│ ├── 00000000000000000001.json
│ └── 00000000000000000002.json
├── part-00000-14e800a0-ed66-4f2a-b973-c33e140ebbdd-c000.snappy.parquet
├── part-00000-76982af1-0bd9-404b-8fb5-d5eb478987ea-c000.snappy.parquet
└── part-00000-f2519f55-be84-44c2-bd11-46ec45b1fe33-c000.snappy.parquet
3 directories, 6 filesWhen comparing the 2nd and 3rd JSON delta_log files, we notice that in addition to the additions and deletions, our schema has now been adjusted.
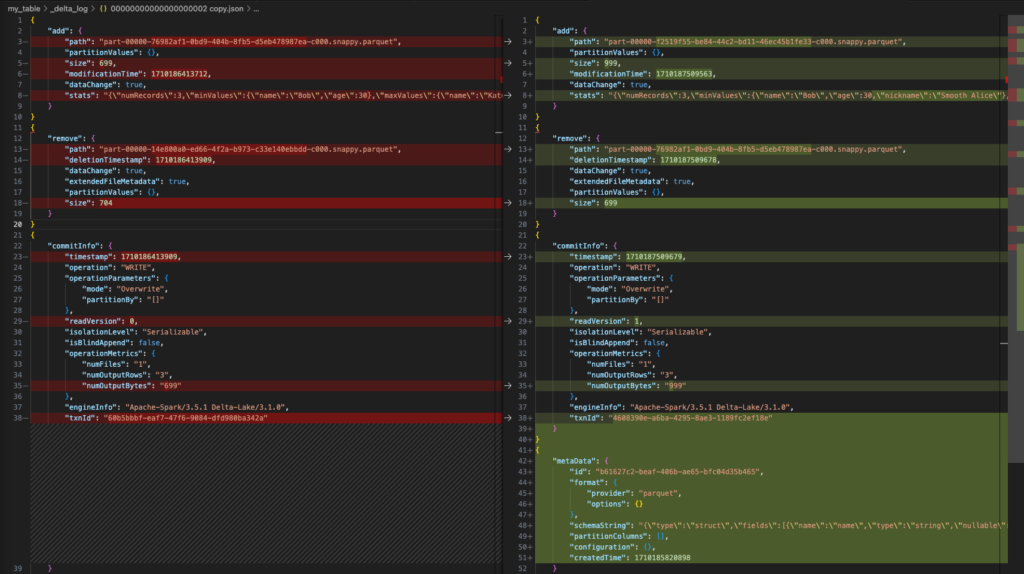
Conclusion
In conclusion, Delta Log offers more than just a means to capture changes in data; it provides a comprehensive solution for tracking alterations in table metadata, including schema modifications and structural adjustments. Our exploration has shed light on several noteworthy attributes of Delta tables:
- Delta format seamlessly combines Parquet files with intelligent JSON metadata logs, offering both efficiency and flexibility.
- With each data write operation, a new JSON meta-log file is generated, ensuring the preservation of previous data Parquet files and JSON delta configuration files.
- Data in Delta tables are continuously appended, guaranteeing that even in the event of unexpected interruptions, such as job termination, you can revert to a prior version with confidence, thanks to the atomicity of changes.
- Historical versions of data remain preserved, even after overwrites, potentially leading to significant data growth. Regular vacuuming is essential to manage this growth effectively.
Embrace these insights as you delve into the world of Delta Log and unleash its full potential in your coding endeavors!
Happy coding!
Filip